
четверг, 20 декабря 2012 г.
воскресенье, 25 ноября 2012 г.
Veritas Volume manager
Сабж используется у нас длительное время , лучший по функционалу , гибкости и надежности . Много раз выручал при выключениях питания , авариях и т.д. В общем , лучший Volume Manager.
Так я думал до позапрошлой недели , когда случился крайне неприятный случай .
Группа Vxvm переезжает с одного хоста на другой , процедура рутинная , проводилась десятки ( а может и сотни ) раз , выполняет младший админ .
Само собой все работы ночью , звонок уже от старшего админа - 'База не поднимается , не может открыть кучу файлов'
При просмотре alert.log возникает чувство deja-vou - список битых файлов странно знаком .... проверяю ...точно !
Файлы с битыми заголовками - только те , которые недавно переносились на новый диск, я сам их копировал при помощи vxassist mirror
Странно - vxdg adddisk отработал абсолютно штатно , эти файлы активно использовались базой до переезда , ошибок не было . Все началось после deport/import.
Поскольку у нас все (почти) организовано правильно , данные зеркалируются на разные Хитачи , то решение было очевидным - отстрелить плексы на этом новом диске ( lun конечно ) . После чего база успешно поднимается , вытираем холодный пот .
А вот если бы не зеркало , то данные мы бы потеряли .
На следующий день был быстро найден баг Veritas - ошибка при инициализации нового диска . Неправильно считалось смещение привата , при deport писалось уже правильное смещение с очевидным результатом .
Все это на версии 5.1 с определенным уровнем патчей , исправление уже есть .
В итоге - все обошлось , но - потеряно время и доверие к ранее отличному продукту .
Так я думал до позапрошлой недели , когда случился крайне неприятный случай .
Группа Vxvm переезжает с одного хоста на другой , процедура рутинная , проводилась десятки ( а может и сотни ) раз , выполняет младший админ .
Само собой все работы ночью , звонок уже от старшего админа - 'База не поднимается , не может открыть кучу файлов'
При просмотре alert.log возникает чувство deja-vou - список битых файлов странно знаком .... проверяю ...точно !
Файлы с битыми заголовками - только те , которые недавно переносились на новый диск, я сам их копировал при помощи vxassist mirror
Странно - vxdg adddisk отработал абсолютно штатно , эти файлы активно использовались базой до переезда , ошибок не было . Все началось после deport/import.
Поскольку у нас все (почти) организовано правильно , данные зеркалируются на разные Хитачи , то решение было очевидным - отстрелить плексы на этом новом диске ( lun конечно ) . После чего база успешно поднимается , вытираем холодный пот .
А вот если бы не зеркало , то данные мы бы потеряли .
На следующий день был быстро найден баг Veritas - ошибка при инициализации нового диска . Неправильно считалось смещение привата , при deport писалось уже правильное смещение с очевидным результатом .
Все это на версии 5.1 с определенным уровнем патчей , исправление уже есть .
В итоге - все обошлось , но - потеряно время и доверие к ранее отличному продукту .
четверг, 4 октября 2012 г.
ZFS дом труба шатал
Случился у нас большой бадабум по питанию , в результате пришлось переводить сервисы в другой датацентр . Как всегда выяснилось что "что-то забыли" и надо разворачивать одну из мелких баз с 0 .
Поскольку времени нет (хватай мешки вокзал отходит) , то решили разместить ее на файловой системе ZFS .
Я уже раньше писал о неудачном ее использовании - оказалось , это были цветочки .
Характер нагрузки этой мелкой базы - почти сплошная случайная запись , всего-то полторы-две тысячи IOPS при малом потоке .Вроде как ерунда .
Но - база резко замедлила свою работу , DBA вынесли мне все мозги .
Наконец аврал закончился , и базу вернули на RAW device .
База как положено шустро заработала , вроде как можно расслабиться , но
этой ночью происходит -
panic: BAD TRAP: type=31 rp=2a1229d6d80 addr=68 mmu_fsr=0 occurred in module "zfs" due to a NULL pointer dereference
Это при снятой нагрузке !
Твою мать ! (с) Э.Картман
Поскольку времени нет (хватай мешки вокзал отходит) , то решили разместить ее на файловой системе ZFS .
Я уже раньше писал о неудачном ее использовании - оказалось , это были цветочки .
Характер нагрузки этой мелкой базы - почти сплошная случайная запись , всего-то полторы-две тысячи IOPS при малом потоке .Вроде как ерунда .
Но - база резко замедлила свою работу , DBA вынесли мне все мозги .
Наконец аврал закончился , и базу вернули на RAW device .
База как положено шустро заработала , вроде как можно расслабиться , но
этой ночью происходит -
panic: BAD TRAP: type=31 rp=2a1229d6d80 addr=68 mmu_fsr=0 occurred in module "zfs" due to a NULL pointer dereference
Это при снятой нагрузке !
Твою мать ! (с) Э.Картман
воскресенье, 23 сентября 2012 г.
Netapp - попытка внедрения
Прошедшие месяцы были посвящены попытке внедрить Netapp
Модель fas3240 , сначала с одной полкой SATA дисков , затем с двумя
Должна была заменить часть AMS 2500 , которая основательно нагружена чтением-записью .
В целом - попытки работы на NetApp очень напоминают прогулки по минному полю
Cначала все замечательно , потом бац - и все вдребезги
Чуть подробнее
Netapp был подключен к отдельному серверу , на котором был поднят оракловый standby .Ключевой момент - успевает ли standby за главной базой (applay lag) , по сути - хватает ли производительности этой полки .
Первая попытка запустить standby на одной полке fas3240 была неудачной
Затем подключили вторую , по уверениям вендора 'работать будет отлично'
Сначала applay lag был 0 , затем начал самопроизвольно прыгать по непонятным причинам , нагрузка на главной базе не росла .По оси Y - время отставания в секундах .

Затем начался период отчетности и нагрузка на основной базе подросла . Для standby это оказалось фатально - производительности полки стало не хватать , сначала умеренно , потом наступила полная катастрофа

В настоящий момент лаг - Current Value 515332
Понятно , что такое отставание уже необратимо, это при том что нагрузка на primary базе давно вернулась к норме .
Netapp подключался к серверу через DNFS , работает действительно быстро по сранению с обычным NFS , но глюков и проблем хватает
В общем , мы пришли к выводу что fas3240 не подходит для наших нагрузок
Модель fas3240 , сначала с одной полкой SATA дисков , затем с двумя
Должна была заменить часть AMS 2500 , которая основательно нагружена чтением-записью .
В целом - попытки работы на NetApp очень напоминают прогулки по минному полю
Cначала все замечательно , потом бац - и все вдребезги
Чуть подробнее
Netapp был подключен к отдельному серверу , на котором был поднят оракловый standby .Ключевой момент - успевает ли standby за главной базой (applay lag) , по сути - хватает ли производительности этой полки .
Первая попытка запустить standby на одной полке fas3240 была неудачной
Затем подключили вторую , по уверениям вендора 'работать будет отлично'

Затем начался период отчетности и нагрузка на основной базе подросла . Для standby это оказалось фатально - производительности полки стало не хватать , сначала умеренно , потом наступила полная катастрофа

В настоящий момент лаг - Current Value 515332
Понятно , что такое отставание уже необратимо, это при том что нагрузка на primary базе давно вернулась к норме .
Netapp подключался к серверу через DNFS , работает действительно быстро по сранению с обычным NFS , но глюков и проблем хватает
В общем , мы пришли к выводу что fas3240 не подходит для наших нагрузок
среда, 25 июля 2012 г.
Криптопопугаи на разных CPU
использовался openssl speed
1649 MHz T3 2998 MHz T4 X5680 @ 3.33GHz X3470 @ 2.93GHz
md5 8192 34095 105260 252229 204936
hmac 8192 36374 108330 244860 204987
aes-256 6116 25630 29512 52654
blowfish-8192 10421 34628 46437 37745
sign dsa's 311 482 12702 10835
private rsa's 13 20 528 444
public rsa's 799 1228 33736 28096
PS. Впечатление по последним трем строкам , на интеле эти алгоритмы считаются аппаратно .
1649 MHz T3 2998 MHz T4 X5680 @ 3.33GHz X3470 @ 2.93GHz
md5 8192 34095 105260 252229 204936
hmac 8192 36374 108330 244860 204987
aes-256 6116 25630 29512 52654
blowfish-8192 10421 34628 46437 37745
sign dsa's 311 482 12702 10835
private rsa's 13 20 528 444
public rsa's 799 1228 33736 28096
PS. Впечатление по последним трем строкам , на интеле эти алгоритмы считаются аппаратно .
вторник, 24 июля 2012 г.
Сравнение Т44 и Т34
Запустили новый танк в работу , результаты наблюдаются интересные .
Сравниваются серверы
Т34 1649 MHz SPARC-T3 512 потоков
T44 2998 MHz SPARC-T4 256 потоков
На них работает одно и тоже приложение - оракловая БД , нагрузку считаем одинаковой .
Процессорная загрузка на Т34
 Процессорная нагрузка на Т44
Процессорная нагрузка на Т44
 Как видим , нагрузка уменьшилась на несколько процентов , что совсем немного . Причина очевидна - потоков выполнения в 2 раза меньше .
Как видим , нагрузка уменьшилась на несколько процентов , что совсем немного . Причина очевидна - потоков выполнения в 2 раза меньше .
Более корректно сравнить Load Average на обеих системах .
Т34 Load Average
 T44 Load Average
T44 Load Average
 LA уменьшилась более чем в 2 раза , что вполне ожидаемо .Таким образом , Т44 действительно быстрее Т34 раза в два , причем это именно рост скорости процессора .
LA уменьшилась более чем в 2 раза , что вполне ожидаемо .Таким образом , Т44 действительно быстрее Т34 раза в два , причем это именно рост скорости процессора .
Из интересного также проявился классический эффект роста нагрузки по вводу-выводу на быстром CPU , причем эффект очень сильный .
Что в свою очередь порождает другие проблемы , но это уже другая история .
Сравниваются серверы
Т34 1649 MHz SPARC-T3 512 потоков
T44 2998 MHz SPARC-T4 256 потоков
На них работает одно и тоже приложение - оракловая БД , нагрузку считаем одинаковой .
Процессорная загрузка на Т34


Более корректно сравнить Load Average на обеих системах .
Т34 Load Average


Из интересного также проявился классический эффект роста нагрузки по вводу-выводу на быстром CPU , причем эффект очень сильный .
Что в свою очередь порождает другие проблемы , но это уже другая история .
среда, 11 июля 2012 г.

вторник, 10 июля 2012 г.
T4 sparc
Прибыли новые сервера с Т4 процессорами .
В работу пока еще не запускали .
Проделали немного замеров - получается быстрее Т3 раза в 2-3 .
В работу пока еще не запускали .
Проделали немного замеров - получается быстрее Т3 раза в 2-3 .
вторник, 22 мая 2012 г.
Бег по граблям , или новый софт
Дерьмовая ситуация с современным софтописанием давно уже стала общим местом , но в последнее время эта ситуация приобрела откровенно безумно-маразматический оттенок .
Ладно , я понимаю , что новый релиз NB сопровождается набором патчей размером в 2 Gb
Я еще могу предположить как происходят реинкарнация ошибок пятилетней давности в драйверах Qlogic-a
Но вчерашняя ситуация - это уже загранью добра и зла .
 Кратко сюжет - продуктовая база стала сильно подтормаживать временами - вплоть до залипания консоли . Сотрудник (Зоркий сокол ) быстро нашел источник проблем - см. картинку .
Кратко сюжет - продуктовая база стала сильно подтормаживать временами - вплоть до залипания консоли . Сотрудник (Зоркий сокол ) быстро нашел источник проблем - см. картинку .
Новая версия ораклового агента EMGrid жрет больше процессора , чем база , которую он должен мониторить . Охренеть .
ЗЫ. Попытки штатного конфигурированя агента вчера успеха не дали .
Ладно , я понимаю , что новый релиз NB сопровождается набором патчей размером в 2 Gb
Я еще могу предположить как происходят реинкарнация ошибок пятилетней давности в драйверах Qlogic-a
Но вчерашняя ситуация - это уже загранью добра и зла .

Новая версия ораклового агента EMGrid жрет больше процессора , чем база , которую он должен мониторить . Охренеть .
ЗЫ. Попытки штатного конфигурированя агента вчера успеха не дали .
понедельник, 21 мая 2012 г.
ZFS vs VxFS - part 2
В пятницу не успел закончить пред. заметку - пришлось срочно убегать .
Итак , ситуация была весьма скверная , основной причиной этого являлась чрезмерная склонность ZFS кэшировать данные . На слабых 'дисках' это проявляется очень хорошо .
После некоторых раздумий было решено переразбить рейд-группы и поменять файловую систему .
Понятно , что для этого понадобилось перенести куда-то лежащие там данные и времени это заняло немало .
Переделка рейдов
Из двух групп по 11 дисков 6 рейда было сделано 4 группы пятого рейда .
Каждая группа приводилась на хост , как и ранее , одним луном .
Файловая система .
Было решено перейти за хорошо знакомую старую добрую VxFS , вот результат

"Почувствуйте разницу"(c)
Понятно , что это не совсем чистое сравнение файловых систем , но подчеркну следующие моменты
1. Число и сами диски остались без изменений
2. Данные после обратного перемещения прежние
3. Характер доступа к данным также не поменялся
В целом замечено , что VxFS более равномерно осуществляет запись , иногда даже уменьшая производительность по IOPS . В результате диски не "заклинивает" на бесконечных 100% device busy
Итак , ситуация была весьма скверная , основной причиной этого являлась чрезмерная склонность ZFS кэшировать данные . На слабых 'дисках' это проявляется очень хорошо .
После некоторых раздумий было решено переразбить рейд-группы и поменять файловую систему .
Понятно , что для этого понадобилось перенести куда-то лежащие там данные и времени это заняло немало .
Переделка рейдов
Из двух групп по 11 дисков 6 рейда было сделано 4 группы пятого рейда .
Каждая группа приводилась на хост , как и ранее , одним луном .
Файловая система .
Было решено перейти за хорошо знакомую старую добрую VxFS , вот результат

"Почувствуйте разницу"(c)
Понятно , что это не совсем чистое сравнение файловых систем , но подчеркну следующие моменты
1. Число и сами диски остались без изменений
2. Данные после обратного перемещения прежние
3. Характер доступа к данным также не поменялся
В целом замечено , что VxFS более равномерно осуществляет запись , иногда даже уменьшая производительность по IOPS . В результате диски не "заклинивает" на бесконечных 100% device busy
пятница, 18 мая 2012 г.
ZFS против VxFS - сравнение
Пару лет назад получили большую полку AMS2500 , SATA 2T disk
Ее прицепили к серверу DWH , на некоторое время вечная проблема нехватки места была решена . Для получения наибольшей отдачи по месту для DWH сделали пару 6 raid group 9+2 . Каждая группа отдавалась на хост как один Lun , сверху решили положить ZFS как продвинутую и современную файловую систему .
Сначала , как всегда , все хорошо работало . Затем народ стал жаловаться , вполне обычно - "все тормозит , запросы медленно выполняются"
Анализ показал , что несмотря на клятвенные заверения DBA , что данные на полке ТОЛЬКО для чтения , на нее идет запись . Причем немалая .
 В результате времена выполнения становились временами просто астрономическими . Busy на дисках - 100%
В результате времена выполнения становились временами просто астрономическими . Busy на дисках - 100%
Более глубокое изучение показало , что ZFS кэширует данные на запись в памяти , а затем пытается сбросить их на диск . Причем такое впечатление , что сбросить все сразу . Результат , понятно , очень плохой
Ее прицепили к серверу DWH , на некоторое время вечная проблема нехватки места была решена . Для получения наибольшей отдачи по месту для DWH сделали пару 6 raid group 9+2 . Каждая группа отдавалась на хост как один Lun , сверху решили положить ZFS как продвинутую и современную файловую систему .
Сначала , как всегда , все хорошо работало . Затем народ стал жаловаться , вполне обычно - "все тормозит , запросы медленно выполняются"
Анализ показал , что несмотря на клятвенные заверения DBA , что данные на полке ТОЛЬКО для чтения , на нее идет запись . Причем немалая .

Более глубокое изучение показало , что ZFS кэширует данные на запись в памяти , а затем пытается сбросить их на диск . Причем такое впечатление , что сбросить все сразу . Результат , понятно , очень плохой
вторник, 24 апреля 2012 г.
После большого перерыва посмотрел и пришел к выводу что блог имеет явный отрицательный крен - сплошные troubles
Решил добавить success story
Итак , некая продуктовая база имеет удаленный стандбай , на который в горячем режиме накатываются изменения . В общем , совершенно стандартная схема , но "есть нюанс" (с) :-)
который заключается в том , что канал предоставляет местный провайдер весьма паршивого качества ( оба паршивые - и канал и пров )
Передача данных весьма сильно тормозит , что приводит к отставанию стандбайной базы от основной .
Разбирательства показали , что в канале часто возникают задержки между пакетами , как итог скорость передачи моментально падает . Пров невменяем , а другие в нашей деревне отсутствуют .
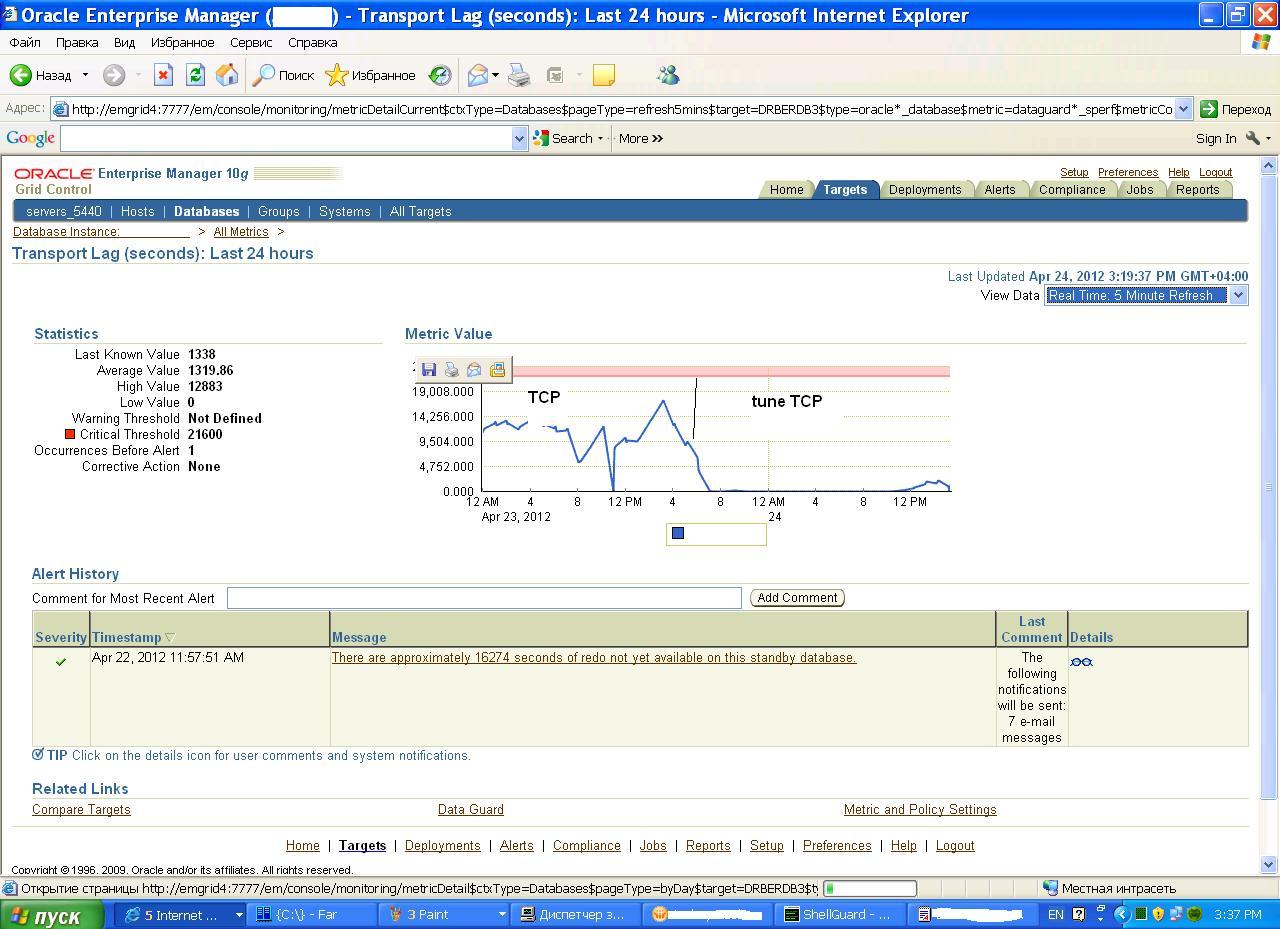
После некоторых экспериментов удалось таки наладить быструю передачу данных на standby - картинка очень наглядна . По оси Y - отставание в секундах , до тюнинга реально был лаг 15-18 тысяч секунд .

Решил добавить success story
Итак , некая продуктовая база имеет удаленный стандбай , на который в горячем режиме накатываются изменения . В общем , совершенно стандартная схема , но "есть нюанс" (с) :-)
который заключается в том , что канал предоставляет местный провайдер весьма паршивого качества ( оба паршивые - и канал и пров )
Передача данных весьма сильно тормозит , что приводит к отставанию стандбайной базы от основной .
Разбирательства показали , что в канале часто возникают задержки между пакетами , как итог скорость передачи моментально падает . Пров невменяем , а другие в нашей деревне отсутствуют .
После некоторых экспериментов удалось таки наладить быструю передачу данных на standby - картинка очень наглядна . По оси Y - отставание в секундах , до тюнинга реально был лаг 15-18 тысяч секунд .
четверг, 2 февраля 2012 г.
Черная пятница
Все-таки в приметах что-то есть .
Сюжет
Внезапно растет цпу-шная нагрузка на сервере , до полного практически останова. Шелл еле живой , база само собой в глубокой заднице .
Все 256 потоков заняты выполняющимися сессиями и трехтысяная очередь к этим же процам . Короче - полный мрак . Иллюстрация степени мрака - на картинке
Но - самое прикольное , что первый раз такое произошло в пятницу 13
второй раз сегодня - тоже пятница

Что-то в этом есть
Сюжет
Внезапно растет цпу-шная нагрузка на сервере , до полного практически останова. Шелл еле живой , база само собой в глубокой заднице .
Все 256 потоков заняты выполняющимися сессиями и трехтысяная очередь к этим же процам . Короче - полный мрак . Иллюстрация степени мрака - на картинке
Но - самое прикольное , что первый раз такое произошло в пятницу 13
второй раз сегодня - тоже пятница

Что-то в этом есть
Подписаться на:
Сообщения (Atom)