Ethernet Fabric - практическое применение ч. 3
Как я уже говорил , для технологии Oracle standby очень важно обеспечить отказоустойчивую и низколатентную связь между серверами . Казалось бы , что проще - взять отдельные коммутаторы типа Циски и соединить с их помощью Primary и Standby
Примерно так :
 Все это будет замечательно работать , пока кто-нибудь случайно не дернет оптику или повредит ее.
Все это будет замечательно работать , пока кто-нибудь случайно не дернет оптику или повредит ее.
Примечание - Primary и Standby лучше размещать на разных площадках , пусть и недалеко друг от друга . Изображен именно такой вариант .
Для борьбы с повреждениями линий надо проложить их несколько
 Сделали транк , все хорошо .
Сделали транк , все хорошо .
Но - у нас остается одна линия от сервера до коммутатора
Ставим двухпортовую сетевую карточку , поднимаем IPMP
 Все хорошо , все замечательно работает , все довольны .
Все хорошо , все замечательно работает , все довольны .
Длится сие счастье ровно до того момента , когда связь между площадками все же падает .
Причина проста - сетевой коммутатор на каждой площадке является критичной точкой отказа - потому что он один
Какой бы он не был надежный ,самого суперименитого вендора , с дважды задублированными блоками питания и прочими элементами внутри - он обязательно выйдет из строя . Или перезагрузится . Это закон жизни , к сожалению проверенный и неоднократно .
Стандартный путь избежания такой ситуации - дублирование критичных узлов . Метод древний , но нечасто применяемый из-за экономии . Но если Вам нужна действительно отказоустойчивая сеть - это необходимо .
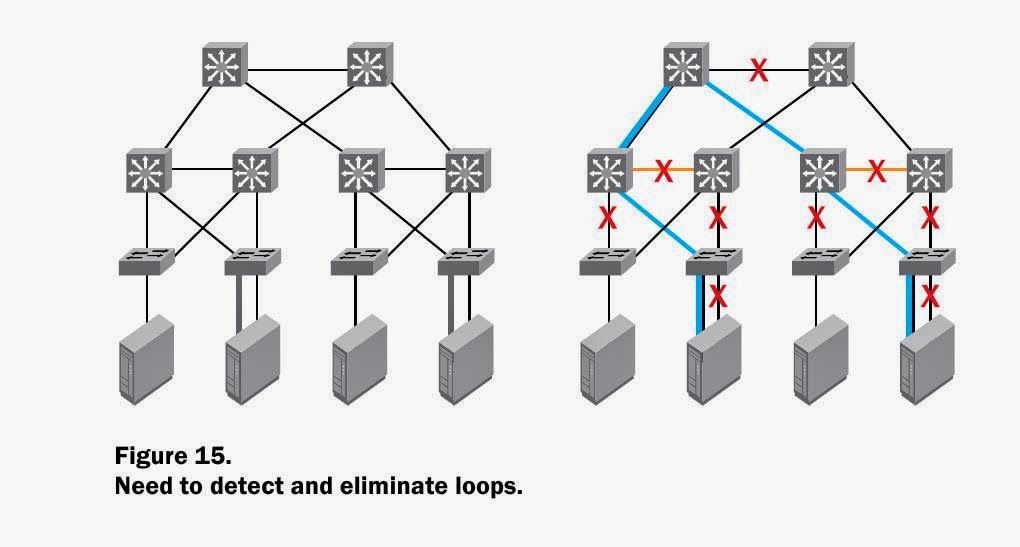
То есть на одной площадке ставится два коммутатора. К каждому коммутатору идет отдельный линк от сервера - полное дублирование
Схема с 4 коммутаторами должна по идее быть вот такой

Вроде бы все хорошо , при выходе из строя коммутатора 1 или 2 IPMP сработает и пакеты будут ходить через 3 и 4 .
Опять таки - все хорошо , все замечательно работает и т.д.
"Но есть нюанс" (с)
Однако представим , что вышел из строя не к.1 , а линия между 1 и 2
С точки зрения сервера - все хорошо , линк между сервером и к.1 не упал - то есть переключения IPMP НЕ происходит .
Можно конечно отказаться от link-base mode в пользу probe-based IPMP. Однако при это встает еще более сложный вопрос - какова надежность probe-base обьекта и как ее обеспечить ?
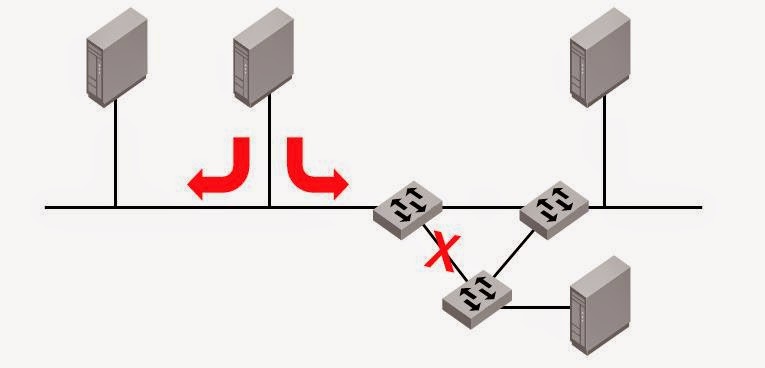
Самое простое решение - соединить коммутаторы 1 и 3

Схема замечтаельная , но вот только ни один обычный Ethernet коммутатор так работат не сможет - кольцо . В лучшем случае после задержки STP поотключает к черту все "лишние " пути .
Решение - Ethernet Fabric
Для нее такая схема является абсолютно штатной .
Для параноидального поднятия отказоустойчивости можно сделать Full mesh , соединив 1--> 3 , 2-->4

В случае выхода одного свича или одного транка между площадками - все работает штатно .
Примерно такая схема реализована в нашем датацентре , посмотрим теперь как это работает .
 Сетевой траффик идет по кратчайшему пути - по линку 1-4 .
Сетевой траффик идет по кратчайшему пути - по линку 1-4 .
В какой-то момент этот линк рвется .
На картинке ниже - сетевой поток по портам коммутатора 1
порт 20 - это линк 1-4
порт 17 и 18 - это линки 1-2 и 1-3

Очень хорошо видно , как поток из порта 20 распределяется по портам 17 и 18 .
Скорость переключения путей в фабрике очень высокая - на уровне пингов задержек не заметно .
После восстановления линка трафик моментально возвращается на кратчайший путь

Вывод - Ethernet Fabric действительно позволяет построить очень надежную сеть .
Как я уже говорил , для технологии Oracle standby очень важно обеспечить отказоустойчивую и низколатентную связь между серверами . Казалось бы , что проще - взять отдельные коммутаторы типа Циски и соединить с их помощью Primary и Standby
Примерно так :
Примечание - Primary и Standby лучше размещать на разных площадках , пусть и недалеко друг от друга . Изображен именно такой вариант .
Для борьбы с повреждениями линий надо проложить их несколько
Но - у нас остается одна линия от сервера до коммутатора
Ставим двухпортовую сетевую карточку , поднимаем IPMP
Длится сие счастье ровно до того момента , когда связь между площадками все же падает .
Причина проста - сетевой коммутатор на каждой площадке является критичной точкой отказа - потому что он один
Какой бы он не был надежный ,самого суперименитого вендора , с дважды задублированными блоками питания и прочими элементами внутри - он обязательно выйдет из строя . Или перезагрузится . Это закон жизни , к сожалению проверенный и неоднократно .
Стандартный путь избежания такой ситуации - дублирование критичных узлов . Метод древний , но нечасто применяемый из-за экономии . Но если Вам нужна действительно отказоустойчивая сеть - это необходимо .
То есть на одной площадке ставится два коммутатора. К каждому коммутатору идет отдельный линк от сервера - полное дублирование
Схема с 4 коммутаторами должна по идее быть вот такой
Вроде бы все хорошо , при выходе из строя коммутатора 1 или 2 IPMP сработает и пакеты будут ходить через 3 и 4 .
Опять таки - все хорошо , все замечательно работает и т.д.
"Но есть нюанс" (с)
Однако представим , что вышел из строя не к.1 , а линия между 1 и 2
С точки зрения сервера - все хорошо , линк между сервером и к.1 не упал - то есть переключения IPMP НЕ происходит .
Можно конечно отказаться от link-base mode в пользу probe-based IPMP. Однако при это встает еще более сложный вопрос - какова надежность probe-base обьекта и как ее обеспечить ?
Самое простое решение - соединить коммутаторы 1 и 3
Схема замечтаельная , но вот только ни один обычный Ethernet коммутатор так работат не сможет - кольцо . В лучшем случае после задержки STP поотключает к черту все "лишние " пути .
Решение - Ethernet Fabric
Для нее такая схема является абсолютно штатной .
Для параноидального поднятия отказоустойчивости можно сделать Full mesh , соединив 1--> 3 , 2-->4
В случае выхода одного свича или одного транка между площадками - все работает штатно .
Примерно такая схема реализована в нашем датацентре , посмотрим теперь как это работает .
В какой-то момент этот линк рвется .
На картинке ниже - сетевой поток по портам коммутатора 1
порт 20 - это линк 1-4
порт 17 и 18 - это линки 1-2 и 1-3
Очень хорошо видно , как поток из порта 20 распределяется по портам 17 и 18 .
Скорость переключения путей в фабрике очень высокая - на уровне пингов задержек не заметно .
После восстановления линка трафик моментально возвращается на кратчайший путь
Вывод - Ethernet Fabric действительно позволяет построить очень надежную сеть .