Ethernet Fabric от Brocade ч. 1
Решил рассказать про успешный опыт использования этой технологии , тем более что складывается впечатление , что в России она совсем не распространена
Для начала - для чего это надо
Начинать придется издалека - с основ , которые сейчас основательно забыты под ворохом навершанных плюшек и костылей .
Небольшой ликбез в общем
Сеть Ethernet изначально создавалась как сеть с негарантированной достакой пакетов .То есть
а. пакеты могут теряться
б. время доставки пакетов в общем случае может быть любым
Пункт а. решается переповторами в вышестоящих протоколах
Пункт б. для большинства приложений не особо важен , где важен решался тупо увеличением скорости сети 10Mb->100Mb->1Gb-10Gb
Все это общеизвестно , однако отметим еще одно важное обстоятельство - Ethernet создавался как протокол доступа точка-точка (MAC-MAC) в одном разделяемом множеством точек сегменте (изначально коаксиале). Это означает что Ethernet подразумевает один путь между точками и не может работать по нескольким сегментам . Это означает также , что одна точка посылает свой пакет второй не зная где она собственно находится .
Усложним схему - добавим Ethernet swith L2
В этом случае свич конечно знает , на каких портах находятся MAC адреса и пересылают пакеты по этой таблице .
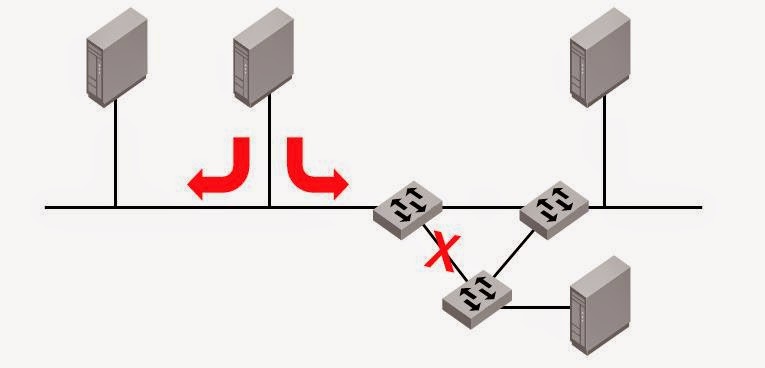
Усложним схему до более реальной - свичей несколько .
Если свич не знает некий MAC адрес то он отправляется другому - может требуемое устройство там .
Проблема в том , что свичи не могут знать , отправляли ли они этот пакет перед этим . В результате возникает хорошо известная проблема зацикливания пакетов в случае нескольких свичей , если они не дай бог соединились кольцом .
Пакеты будут бесконечно бегать по треугольнику , свичи перегрузятся и сеть перестанет работать .
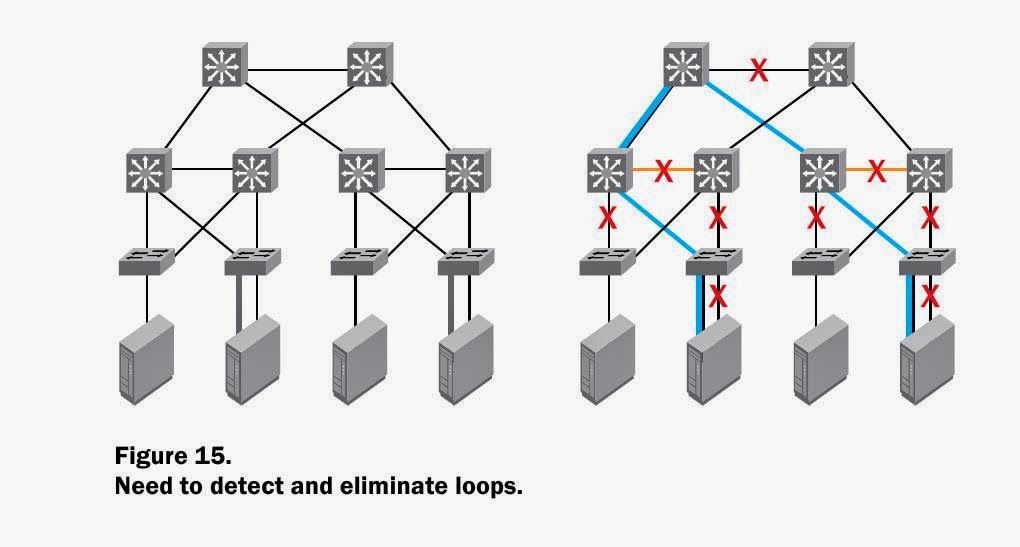
Для решения такой проблемы был придуман костыль STP , блокирующий порты .
Казалось , бы все замечательно .
Но - время срабатывания STP не моментальное , и сеть на какое-то время становится полностью . Само собой , невозможность передавать Ethernet пакеты по нескольким путям ограничивает скорость и понижает надежность .
Все дублирующие линки будут положены . ( картинки сперты из материалов Brocade)
Со всеми этими недостатками особо не парились , пока Ethernet сети использовались для офиса и Интернета и пока не появился 10g в локальных сетях .
Тут же возник соблазн использовать 10g для замены FC SAN и появилась технология FCOE .
Очеь быстро выяснилось , что на обычном Ethernet более-менее серьезный дисковый ввод-вывод работает плохо .
Причины очевидны - даже при просмотре потокового видео задержки в 3-5 мс особо не заметны , а вот для нагруженного сервера это заметно очень сильно .Особенно если эти задержки хаотичны и происходят на записи редологов.
64 bytes from 10.0.2.120 : icmp_seq=1265. time=0.603 ms
64 bytes from 10.0.2.120 : icmp_seq=1266. time=0.529 ms
64 bytes from 10.0.2.120 : icmp_seq=1267. time=4.103 ms
64 bytes from 10.0.2.120 : icmp_seq=1268. time=0.450 ms
64 bytes from 10.0.2.120 : icmp_seq=1269. time=0.573 ms
Более того , некоторые решения/приложения требуют минимальных задержек просто при передаче данных , без всякого IO .
Одним из таких решений является Oracle Standby in Max. availability mode .
Standby (очень грубо ) является зеркалом оракловой базы , изменения
передаются то сети . В случае задержек передачи в указанном режиме
Primary начинает автоматически подтормаживать , чтобы сохранить синхронность . Само собой это крайне негативно сказывается на работе приложений , завязанных на эту базу .
С указанной ситуаций , к сожалению , пришлось столкнуться .
Primary и Standby соединялись локалькной сетью с скоростью 1Gb
Такой скорости более чем достаточно для передачи , но периодические увеличения задержек крайне негативно влияли на работу
На рисунке - характерный пик ожиданий на базе
Отмечу , что локальная сеть собрана совершенно правильно , мощности Cisco хватает с избытком .
Но задержки , возникающие в обычной ethernet - неизбежны .