Дерьмовая ситуация с современным софтописанием давно уже стала общим местом , но в последнее время эта ситуация приобрела откровенно безумно-маразматический оттенок .
Ладно , я понимаю , что новый релиз NB сопровождается набором патчей размером в 2 Gb
Я еще могу предположить как происходят реинкарнация ошибок пятилетней давности в драйверах Qlogic-a
Но вчерашняя ситуация - это уже загранью добра и зла .
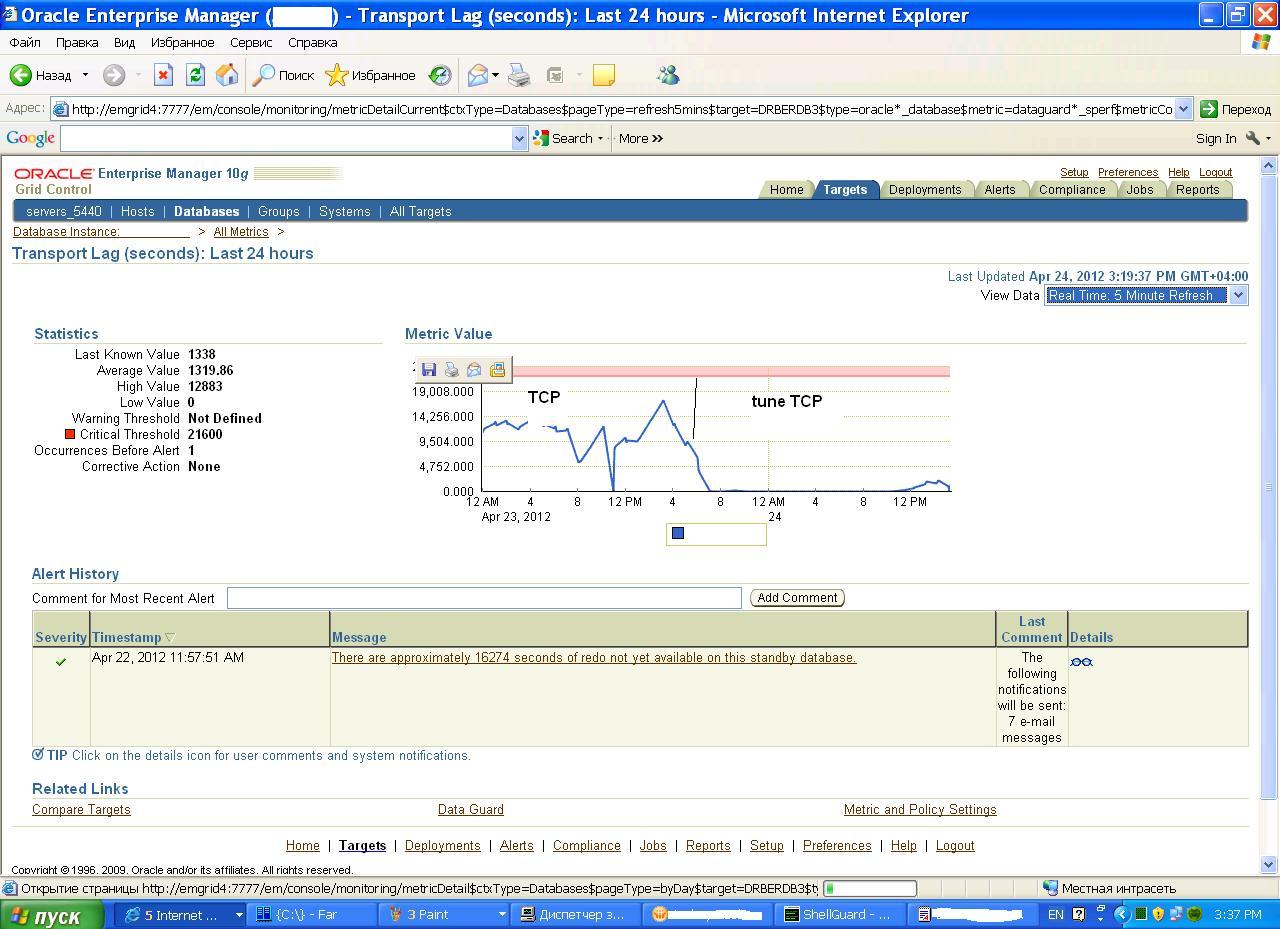
 Кратко сюжет - продуктовая база стала сильно подтормаживать временами - вплоть до залипания консоли . Сотрудник (Зоркий сокол ) быстро нашел источник проблем - см. картинку .
Кратко сюжет - продуктовая база стала сильно подтормаживать временами - вплоть до залипания консоли . Сотрудник (Зоркий сокол ) быстро нашел источник проблем - см. картинку .
Новая версия ораклового агента EMGrid жрет больше процессора , чем база , которую он должен мониторить . Охренеть .
ЗЫ. Попытки штатного конфигурированя агента вчера успеха не дали .
Ладно , я понимаю , что новый релиз NB сопровождается набором патчей размером в 2 Gb
Я еще могу предположить как происходят реинкарнация ошибок пятилетней давности в драйверах Qlogic-a
Но вчерашняя ситуация - это уже загранью добра и зла .

Новая версия ораклового агента EMGrid жрет больше процессора , чем база , которую он должен мониторить . Охренеть .
ЗЫ. Попытки штатного конфигурированя агента вчера успеха не дали .